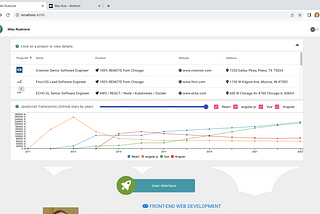
Mau Ruais JEST better than KARMABoth Jest and Karma are popular JavaScript testing frameworks, but they serve different purposes and have distinct features. Let’s explore…Jul 10Jul 10
Mau Ruamruanova.com now on Angular 18I just updated my career portfolio to Angular 18 https://mruanova.com/May 24May 24
Mau Ruamruanova.com now on Angular 17I just updated my career portfolio to Angular 17 https://mruanova.com/Nov 9, 2023Nov 9, 2023
Mau RuaAngular 16I upgraded my career portfolio to Angular 16 https://mruanova.com/Oct 18, 2023Oct 18, 2023
Mau RuaChatGPT list of images in JavaScriptcan you please generate a carousel that renders a list of images in javascript?Jan 6, 2023Jan 6, 2023
Mau RuaAngular 15I upgraded my career portfolio to Angular 15 https://mruanova.com/Jan 6, 2023Jan 6, 2023
Mau RuaI am testing ChatGPT… can you please write a poem about dogs and middle child syndrome?Sure, here is a poem about dogs and middle child syndrome:Jan 6, 2023Jan 6, 2023
Mau RuaClient-facing skillsClient-facing skills, also known as Customer-facing skills, are abilities or soft skills necessary to face the client, interact directly…Jun 7, 2022Jun 7, 2022