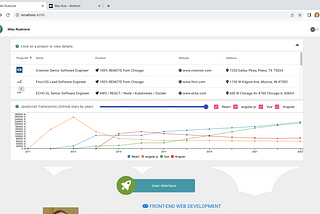
Mau Ruamruanova.com now on Angular 17I just updated my career portfolio to Angular 17 https://mruanova.com/1 min read·Nov 9, 2023----
Mau RuaAngular 16I upgraded my career portfolio to Angular 16 https://mruanova.com/1 min read·Oct 18, 2023----
Mau RuaChatGPT list of images in JavaScriptcan you please generate a carousel that renders a list of images in javascript?2 min read·Jan 6, 2023----
Mau RuaAngular 15I upgraded my career portfolio to Angular 15 https://mruanova.com/1 min read·Jan 6, 2023----
Mau RuaI am testing ChatGPT… can you please write a poem about dogs and middle child syndrome?Sure, here is a poem about dogs and middle child syndrome:1 min read·Jan 6, 2023----
Mau RuaClient-facing skillsClient-facing skills, also known as Customer-facing skills, are abilities or soft skills necessary to face the client, interact directly…1 min read·Jun 7, 2022----
Mau RuaThe term ng is not recognizedError: The term ng is not recognized as the name of a cmdlet, function, script file, or operable program.1 min read·May 5, 2022----
Mau Ruacareer portfolio in Angular 13I updated my career portfolio using Angular 13 https://mruanova.com1 min read·Apr 26, 2022----